1. Overview
Apache StormCrawler is an open source collection of resources for building low-latency, scalable web crawlers on Apache Storm. It is provided under the Apache License and is written mostly in Java.
The aims of StormCrawler are to help build web crawlers that are:
-
Scalable
-
Low latency
-
Easy to extend
-
Polite yet efficient
StormCrawler is both a library and a collection of reusable components designed to help developers build custom web crawlers with ease. Getting started is simple — the Maven archetypes allow you to quickly scaffold a new project, which you can then adapt to fit your specific needs.
In addition to its core modules, StormCrawler offers a range of external resources that can be easily integrated into your project. These include spouts and bolts for OpenSearch, as well as a ParserBolt that leverages Apache Tika to handle various document formats and many more.
StormCrawler is well-suited for scenarios where URLs to fetch and parse arrive as continuous streams, but it also performs exceptionally in large-scale, recursive crawls where low latency is essential. The project is actively maintained, widely adopted in production environments, and supported by an engaged community.
You can find links to recent talks and demos later in this document, showcasing real-world applications and use cases.
2. Key Features
Here is a short list of provided features:
-
Integration with URLFrontier for distributed URL management
-
Pluggable components (Spouts and Bolts from Apache Storm) for flexibility and modularity — adding custom components is straightforward
-
Support for Apache Tika for document parsing via
ParserBolt -
Integration with OpenSearch and Apache Solr for indexing and status storage
-
Option to store crawled data as WARC (Web ARChive) files
-
Support for headless crawling using Playwright
-
Support for LLM-based advanced text extraction
-
Proxy support for distributed and controlled crawling
-
Flexible and pluggable filtering mechanisms:
-
URL Filters for pre-fetch filtering
-
Parse Filters for post-fetch content filtering
-
-
Built-in support for crawl metrics and monitoring
-
Configurable politeness policies (e.g., crawl delay, user agent management)
-
Robust HTTP fetcher based on Apache HttpComponents or OkHttp.
-
MIME type detection and response-based filtering
-
Support for parsing and honoring
robots.txtand sitemaps -
Stream-based, real-time architecture using Apache Storm — suitable for both recursive and one-shot crawling tasks
-
Can run in both local and distributed environments
-
Apache Maven archetypes for quickly bootstrapping new crawler projects
-
Actively developed and used in production by multiple organizations
3. Quick Start
These instructions should help you get Apache StormCrawler up and running in 5 to 15 minutes.
3.1. Prerequisites
To run StormCrawler, you will need Java SE 17 or later.
Additionally, since we’ll be running the required Apache Storm cluster using Docker Compose, make sure Docker is installed on your operating system.
3.2. Terminology
Before starting, we will give a quick overview of essential Storm concepts and terminology that you need to know before starting with StormCrawler:
-
Topology: A topology is the overall data processing graph in Storm, consisting of spouts and bolts connected together to perform continuous, real-time computations.
-
Spout: A spout is a source component in a Storm topology that emits streams of data into the processing pipeline.
-
Bolt: A bolt processes, transforms, or routes data streams emitted by spouts or other bolts within the topology.
-
Flux: In Apache Storm, Flux is a declarative configuration framework that enables you to define and run Storm topologies using YAML files instead of writing Java code. This simplifies topology management and deployment.
-
Frontier: In the context of a web crawler, the Frontier is the component responsible for managing and prioritizing the list of URLs to be fetched next.
-
Seed: In web crawling, a seed is an initial URL or set of URLs from which the crawler starts its discovery and fetching process.
3.3. Bootstrapping a StormCrawler Project
You can quickly generate a new StormCrawler project using the Maven archetype:
mvn archetype:generate -DarchetypeGroupId=org.apache.stormcrawler \
-DarchetypeArtifactId=stormcrawler-archetype \
-DarchetypeVersion=<CURRENT_VERSION>PowerShell
mvn archetype:generate `
"-DarchetypeGroupId=org.apache.stormcrawler" `
"-DarchetypeArtifactId=stormcrawler-archetype" `
"-DarchetypeVersion=<CURRENT_VERSION>"Be sure to replace <CURRENT_VERSION> with the latest released version of StormCrawler, which you can find on search.maven.org.
During the process, you’ll be prompted to provide the following:
-
groupId(e.g.com.mycompany.crawler) -
artifactId(e.g.stormcrawler) -
Version
-
Package name
-
User agent details
| Specifying a user agent is important for crawler ethics because it identifies your crawler to websites, promoting transparency and allowing site owners to manage or block requests if needed. Be sure to provide a crawler information website as well. |
The archetype will generate a fully-structured project including:
-
A pre-configured
pom.xmlwith the necessary dependencies -
Default resource files
-
A sample
crawler.fluxconfiguration -
A sample YAML configuration file (
crawler-conf.yaml)
After generation, navigate into the newly created directory (named after the artifactId you specified).
| You can learn more about the architecture and how each component works together if you look into the architecture documentation. By exploring that part of the documentation, you can gain a better understanding of how StormCrawler performs crawling and how bolts, spouts, as well as parse and URL filters, collaborate in the process. |
3.3.1. Docker Compose Setup
Below is a simple docker-compose.yml configuration to spin up URLFrontier, Zookeeper, Storm Nimbus, Storm Supervisor, and the Storm UI:
services:
zookeeper:
image: zookeeper:3.9.3
container_name: zookeeper
restart: always
nimbus:
image: storm:latest
container_name: nimbus
hostname: nimbus
command: storm nimbus
depends_on:
- zookeeper
restart: always
supervisor:
image: storm:latest
container_name: supervisor
command: storm supervisor -c worker.childopts=-Xmx2g
depends_on:
- nimbus
- zookeeper
restart: always
ui:
image: storm:latest
container_name: ui
command: storm ui
depends_on:
- nimbus
restart: always
ports:
- "127.0.0.1:8080:8080"
urlfrontier:
image: crawlercommons/url-frontier:latest
container_name: urlfrontier
restart: always
ports:
- "127.0.0.1:7071:7071"Notes:
-
This example Docker Compose uses the official Apache Storm and Apache Zookeeper images.
-
URLFrontier is an additional service used by StormCrawler to act as Frontier. Please note, that we also offer other Frontier implementations like OpenSearch or Apache Solr.
-
Ports may need adjustment depending on your environment.
-
The Storm UI runs on port 8080 by default.
-
Ensure network connectivity between services; Docker Compose handles this by default.
After setting up your Docker Compose, you should start it up:
docker compose up -dCheck the logs and see if every service is up and running:
docker compose logs -fNext, access the Storm UI via http://localhost:8080 and check that a Storm Nimbus as well as a Storm Supervisor is available.
3.3.2. Compile
Build the generated archetype by running
mvn packageThis will create a uberjar named ${artifactId}-${version}.jar (matches the artifact id and the version specified during the archetype generation) in your target directory.
3.3.3. Inject Your First Seeds
Now you are ready to insert your first seeds into URLFrontier. To do so, create a file seeds.txt containing your seeds:
https://stormcrawler.apache.orgAfter you have saved it, we need to inject the seeds into URLFrontier. This can be done by running URLFrontiers client:
java -cp target/${artifactId}-${version}.jar crawlercommons.urlfrontier.client.Client PutURLs -f seeds.txtPowerShell
java -cp target/$artifactId-$version.jar crawlercommons.urlfrontier.client.Client PutURLs -f seeds.txtwhere seeds.txt is the previously created file containing URLs to inject, with one URL per line.
3.3.4. Run Your First Crawl
Now it is time to run our first crawl. To do so, we need to start our crawler topology in distributed mode and deploy it on our Storm Cluster.
docker run --network ${NETWORK} -it \
--rm \
-v "$(pwd)/crawler-conf.yaml:/apache-storm/crawler-conf.yaml" \
-v "$(pwd)/crawler.flux:/apache-storm/crawler.flux" \
-v "$(pwd)/${artifactId}-${version}.jar:/apache-storm/${artifactId}-${version}.jar" \
storm:latest \
storm jar ${artifactId}-${version}.jar org.apache.storm.flux.Flux --remote crawler.fluxPowerShell
docker run --network $NETWORK -it `
--rm `
-v "${PWD}/crawler-conf.yaml:/apache-storm/crawler-conf.yaml" `
-v "${PWD}/crawler.flux:/apache-storm/crawler.flux" `
-v "${PWD}/$artifactId-$version.jar:/apache-storm/$artifactId-$version.jar" `
storm:latest `
storm jar $artifactId-$version.jar org.apache.storm.flux.Flux --remote crawler.fluxwhere ${NETWORK} is the name of the Docker network of the previously started Docker Compose. You can find this name by running
docker network lsAfter running the storm jar command, you should carefully monitor the logs via
docker compose logs -fas well as the Storm UI. It should now list a running topology.
In the default archetype, the fetched content is printed out to the default system out print stream.
| In a Storm topology defined with Flux, parallelism specifies the number of tasks or instances of a spout or bolt to run concurrently, enabling scalable and efficient processing. In the archetype every component is set to a parallelism of 1. |
Congratulations! You learned how to start your first simple crawl using Apache StormCrawler.
Feel free to explore the rest of our documentation to build more complex crawler topologies.
3.4. Summary
This document shows how simple it is to get Apache StormCrawler up and running and to run a simple crawl.
4. Understanding StormCrawler’s Architecture
4.1. Architecture Overview
Apache StormCrawler is built as a distributed, stream-oriented web crawling system on top of Apache Storm. Its architecture emphasizes clear separation between crawl control and content processing, with the URL frontier acting as the central coordination point.
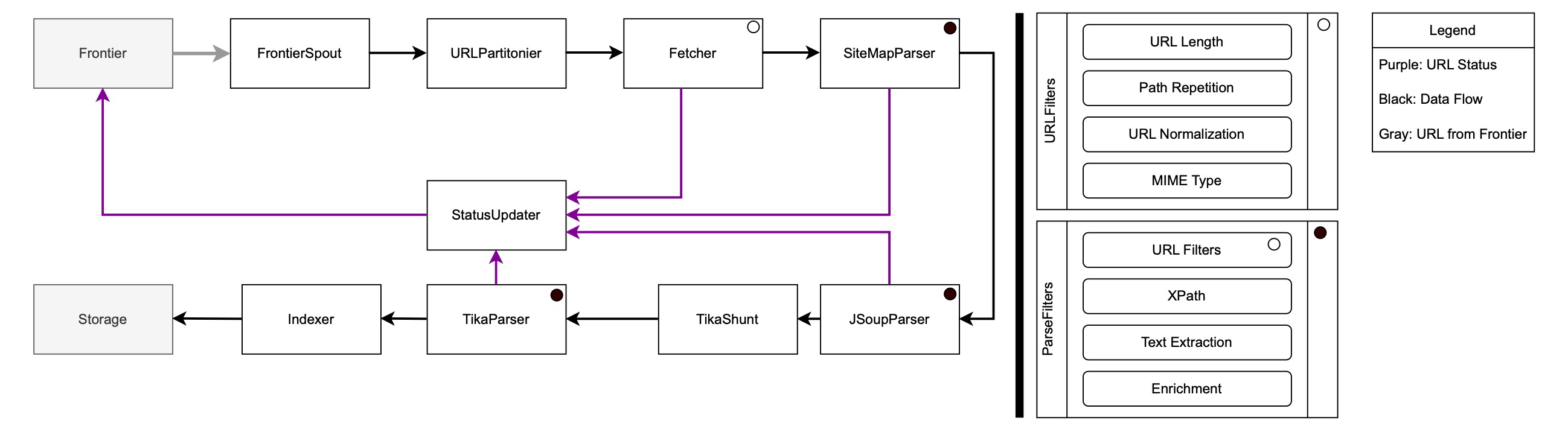
Figure 1 illustrates StormCrawler’s stream-processing crawl pipeline, built on Apache Storm. The architecture is intentionally modular and centers around two core abstractions:
-
The URL frontier: decides what to crawl and when
-
The parsing and indexing pipeline: decides what to extract, keep, and store
Black arrows show the main data flow, gray arrows represent URLs taken from the frontier, and purple arrows indicate URL status updates fed back to the frontier.
4.1.1. Crawl Flow and Core Components
The crawl begins with the Frontier, which is responsible for scheduling,
prioritization, politeness, and retry logic. URLs are emitted by a
Spout (e.g., AggregationSpout, SQLSpout) and partitioned by the URLPartitioner, typically using the
host as a key to enforce politeness constraints.
The Fetcher retrieves web resources and emits both the fetched content and
associated metadata such as HTTP status codes, headers, and MIME types. Based
on the content type, documents are routed to specialized parsers, including
SiteMapParser, JSoupParser for HTML content, and ParserBolt (Tika module) for binary
formats via Apache Tika.
Parsed content is then sent to the Indexer and persisted by the Storage
layer. Throughout the pipeline, fetch and parse outcomes are reported to the
StatusUpdater, which feeds URL status information back to the frontier,
closing the crawl feedback loop.
4.1.2. URL Filters
URL Filters determine whether a URL should be accepted, rejected, or modified before it is scheduled for fetching. They operate on seed URLs, discovered links, and redirect targets, ensuring that only crawl-worthy URLs enter the frontier.
In Figure 1, URL Filters are conceptually positioned between link discovery and the frontier. Their primary role is to control crawl scope and prevent frontier explosion.
Typical URL Filters include:
-
URL Length: rejects excessively long URLs that often indicate session IDs or crawler traps.
-
Path Repetition: detects repeating path segments that can lead to infinite crawl loops.
-
URL Normalization: canonicalizes URLs by removing fragments, sorting query parameters, or enforcing consistent schemes.
-
MIME Type: avoids scheduling URLs unlikely to yield useful content.
By applying these filters early, StormCrawler prevents unnecessary fetches and maintains an efficient, focused crawl.
4.1.3. Parse Filters
Parse Filters operate after content has been successfully fetched and parsed. They allow fine-grained control over how extracted data and outgoing links are processed.
Parse Filters are applied within the parsing bolts, following parsing by
SiteMapParser, JSoupParser, or ParserBolt (Tika). They can modify extracted text,
metadata, and links before the content is indexed or new URLs are emitted.
Common Parse Filters include:
-
URL Filters (post-parse): further refine outgoing links extracted from content.
-
XPath: extract structured fields from HTML documents.
-
Text Extraction: control which parts of a document contribute to the indexed text.
-
Enrichment: add custom metadata such as language detection, entity tags, or domain-specific signals.
Parse Filters enable domain-specific logic without coupling it directly to the crawler’s core components.
4.1.4. Interaction Between URL Filters and Parse Filters
URL Filters focus on deciding what should be crawled, while Parse Filters focus on deciding what should be kept and how it should be interpreted.
5. Understanding StormCrawler’s Internals
5.1. Status Stream
The Apache StormCrawler components rely on two Apache Storm streams: the default one and another one called status.
The aim of the status stream is to pass information about URLs to a persistence layer. Typically, a bespoke bolt will take the tuples coming from the status stream and update the information about URLs in some sort of storage (e.g., OpenSearch, HBase, etc…), which is then used by a Spout to send new URLs down the topology.
This is critical for building recursive crawls (i.e., you discover new URLs and not just process known ones). The default stream is used for the URL being processed and is generally used at the end of the pipeline by an indexing bolt (which could also be OpenSearch, HBase, etc…), regardless of whether the crawler is recursive or not.
Tuples are emitted on the status stream by the parsing bolts for handling outlinks but also to notify that there has been a problem with a URL (e.g., unparsable content). It is also used by the fetching bolts to handle redirections, exceptions, and unsuccessful fetch status (e.g., HTTP code 400).
A bolt which sends tuples on the status stream declares its output in the following way:
declarer.declareStream(
org.apache.stormcrawler.Constants.StatusStreamName,
new Fields("url", "metadata", "status"));As you can see for instance in SimpleFetcherBolt.
The Status enum has the following values:
-
DISCOVERED:: outlinks found by the parsers or "seed" URLs emitted into the topology by one of the spouts or "injected" into the storage. The URLs can be already known in the storage.
-
REDIRECTION:: set by the fetcher bolts.
-
FETCH_ERROR:: set by the fetcher bolts.
-
ERROR:: used by either the fetcher, parser, or indexer bolts.
-
FETCHED:: set by the DummyIndexer bolt (see below).
The difference between FETCH_ERROR and ERROR is that the former is possibly transient whereas the latter is terminal. The bolt which is in charge of updating the status (see below) can then decide when and whether to schedule a new fetch for a URL based on the status value.
The DummyIndexer is useful for notifying the storage layer that a URL has been successfully processed, i.e., fetched, parsed, and anything else we want to do with the main content. It must be placed just before the StatusUpdaterBolt and sends a tuple for the URL on the status stream with a Status value of fetched.
The class AbstractStatusUpdaterBolt can be extended to handle status updates for a specific backend. It has an internal cache of URLs with a discovered status so that they don’t get added to the backend if they already exist, which is a simple but efficient optimisation. It also uses DefaultScheduler to compute a next fetch date and calls MetadataTransfer to filter the metadata that will be stored in the backend.
In most cases, the extending classes will just need to implement the method store(String URL, Status status, Metadata metadata, Date nextFetch) and handle their own initialisation in prepare(). You can find an example of a class which extends it in the StatusUpdaterBolt for OpenSearch.
5.1.1. AdaptiveScheduler
The AdaptiveScheduler extends the DefaultScheduler and adjusts the fetch interval based on whether a page has changed since the last fetch (detected via MD5 signature comparison). If the page changed, the interval shrinks toward a minimum; if unchanged, it grows toward a maximum. This avoids unnecessary re-fetches of static pages while keeping dynamic pages fresh.
Configuration example:
scheduler.class: "org.apache.stormcrawler.persistence.AdaptiveScheduler"
scheduler.adaptive.setLastModified: true
scheduler.adaptive.fetchInterval.min: 60
scheduler.adaptive.fetchInterval.max: 20160
scheduler.adaptive.fetchInterval.rate.incr: .5
scheduler.adaptive.fetchInterval.rate.decr: .5The AdaptiveScheduler requires the MD5SignatureParseFilter to be configured so that the signature metadata field is populated.
5.2. Bolts
5.2.1. Fetcher Bolts
There are actually two different bolts for fetching the content of URLs:
Both declare the same output:
declarer.declare(new Fields("url", "content", "metadata"));
declarer.declareStream(
org.apache.stormcrawler.Constants.StatusStreamName,
new Fields("url", "metadata", "status"));with the status stream being used for handling redirections, restrictions by robots directives, or fetch errors, whereas the default stream gets the binary content returned by the server as well as the metadata to the following components (typically a parsing bolt).
Both use the same Protocols implementations and URLFilters to control the redirections.
The FetcherBolt has an internal set of queues where the incoming URLs are placed based on their hostname/domain/IP (see config fetcher.queue.mode) and a number of FetchingThreads (config fetcher.threads.number – 10 by default) which pull the URLs to fetch from the FetchQueues. When doing so, they make sure that a minimal amount of time (set with fetcher.server.delay – default 1 sec) has passed since the previous URL was fetched from the same queue. This mechanism ensures that we can control the rate at which requests are sent to the servers. A FetchQueue can also be used by more than one FetchingThread at a time (in which case fetcher.server.min.delay is used), based on the value of fetcher.threads.per.queue.
Incoming tuples spend very little time in the execute method of the FetcherBolt as they are put in the FetchQueues, which is why you’ll find that the value of Execute latency in the Storm UI is pretty low. They get acked later on, after they’ve been fetched. The metric to watch for in the Storm UI is Process latency.
The SimpleFetcherBolt does not do any of this, hence its name. It just fetches incoming tuples in its execute method and does not do multi-threading. It does enforce politeness by checking when a URL can be fetched and will wait until it is the case. It is up to the user to declare multiple instances of the bolt in the Topology class and to manage how the URLs get distributed across the instances of SimpleFetcherBolt, often with the help of the URLPartitioner.
5.3. Indexer Bolts
The purpose of crawlers is often to index web pages to make them searchable. The project contains resources for indexing with popular search solutions such as:
All of these extend the class AbstractIndexerBolt.
The core module also contains a simple indexer which dumps the documents into the standard output – useful for debugging – as well as a DummyIndexer.
The basic functionalities of filtering a document to index, mapping the metadata (which determines which metadata to keep for indexing and under what field name), or using the canonical tag (if any) are handled by the abstract class. This allows implementations to focus on communication with the indexing APIs.
Indexing is often the penultimate component in a pipeline and takes the output of a Parsing bolt on the standard stream. The output of the indexing bolts is on the status stream:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declareStream(
org.apache.stormcrawler.Constants.StatusStreamName,
new Fields("url", "metadata", "status"));
}The DummyIndexer is used for cases where no actual indexing is required. It simply generates a tuple on the status stream so that any StatusUpdater bolt knows that the URL was processed successfully and can update its status and scheduling in the corresponding backend.
You can easily build your own custom indexer to integrate with other storage systems, such as a vector database for semantic search, a graph database for network analysis, or any other specialized data store. By extending AbstractIndexerBolt, you only need to implement the logic to communicate with your target system, while StormCrawler handles the rest of the pipeline and status updates.
5.4. Parser Bolts
5.4.1. JSoupParserBolt
The JSoupParserBolt can be used to parse HTML documents and extract the outlinks, text, and metadata it contains. If you want to parse non-HTML documents, use the Tika-based ParserBolt from the external modules.
This parser calls the URLFilters and ParseFilters defined in the configuration. Please note that it calls MetadataTransfer prior to calling the ParseFilters. If you create new Outlinks in your , you’ll need to make sure that you use MetadataTransfer there to inherit the Metadata from the parent document.
The JSoupParserBolt automatically identifies the charset of the documents. It uses the status stream to report parsing errors but also for the outlinks it extracts from a page. These would typically be used by an extension of AbstractStatusUpdaterBolt and persisted in some form of storage.
5.4.2. SiteMapParserBolt
StormCrawler can handle sitemap files thanks to the SiteMapParserBolt. This bolt should be placed before the standard ParserBolt in the topology, as illustrated in crawler.flux topology.
The reason for this is that the SiteMapParserBolt acts as a filter: it passes on any incoming tuples to the default stream so that they get processed by the ParserBolt, unless the tuple contains isSitemap=true in its metadata, in which case the SiteMapParserBolt will parse it itself. Any outlinks found in the sitemap files are then emitted on the .
The SiteMapParserBolt applies any configured ParseFilters to the documents it parses and, just like its equivalent for HTML pages, it uses MetadataTransfer to populate the Metadata objects for the Outlinks it finds.
5.4.3. FeedParserBolt
The FeedParserBolt handles RSS and Atom feeds. Like the SiteMapParserBolt, it acts as a filter in the topology: it passes non-feed tuples through on the default stream, and only parses tuples whose metadata contains isFeed=true. Discovered feed entries are emitted on the status stream. The bolt is configured with feed.sniffContent (to auto-detect feeds) and feed.filter.hours.since.published (to discard old entries).
5.4.4. URLPartitionerBolt
The URLPartitionerBolt partitions incoming URLs by host, domain, or IP address (controlled by partition.url.mode). It is typically placed before a fetcher bolt to ensure that URLs destined for the same server are routed to the same bolt instance, enabling effective politeness enforcement. It uses the URLPartitioner utility internally.
5.4.5. StatusEmitterBolt
The StatusEmitterBolt is an abstract base class for bolts that emit tuples on both the default stream and the status stream. It provides utility methods for emitting status updates (e.g., errors, redirections, discovered URLs). The fetcher and parser bolts (FetcherBolt, SimpleFetcherBolt, JSoupParserBolt, SiteMapParserBolt, FeedParserBolt) all extend this class.
5.5. Spouts
StormCrawler provides several spout implementations for feeding URLs into the topology:
5.5.1. FileSpout
The FileSpout reads seed URLs from UTF-8 text files and loads them into memory. Each line is parsed using StringTabScheme into a URL and optional metadata (tab-separated). This is useful for one-off crawls with a known list of URLs.
5.5.2. MemorySpout
The MemorySpout stores URLs in an in-memory priority queue. It is intended for testing and debugging in local mode or with a single worker. It can be used with MemoryStatusUpdater to emulate a recursive crawl without an external storage backend.
5.5.3. AbstractQueryingSpout
The AbstractQueryingSpout is the abstract base class for spouts that query a storage backend for URLs to fetch. External module spouts such as AggregationSpout (OpenSearch), SolrSpout, SQLSpout, and the URLFrontier Spout all extend this class. It handles throttling, acking, and coordination with the URL buffer (urlbuffer.class).
5.6. Filters
5.6.1. Parse Filters
ParseFilters are called from parsing bolts such as JSoupParserBolt and SiteMapParserBolt to extract data from web pages. The extracted data is stored in the Metadata object. ParseFilters can also modify the Outlinks and, in that sense, act as URLFilters.
ParseFilters need to implement the interface ParseFilter, which defines three methods:
public void filter(String URL, byte[] content, DocumentFragment doc, ParseResult parse);
public void configure(Map stormConf, JsonNode filterParams);
public boolean needsDOM();-
The
filtermethod is where the extraction occurs. ParseResult objects contain the outlinks extracted from the document as well as a Map of String to ParseData, where the String is the URL of a subdocument or the main document itself. ParseData objects contain Metadata, binary content, and text for the subdocuments, which is useful for indexing subdocuments independently of the main document. -
The
needsDOMmethod indicates whether the ParseFilter instance requires the DOM structure. If no ParseFilters need it, the parsing bolt will skip generating the DOM, slightly improving performance. -
The
configuremethod takes a JSON object loaded by the wrapper class ParseFilters. The Storm configuration map can also be used to configure the filters, as described in Configuration.
Here is the default JSON configuration file for ParseFilters. The configuration allows multiple instances of the same filter class with different parameters and supports complex parameter objects. ParseFilters are executed in the order they appear in the JSON file.
Provided ParseFilters
-
CollectionTagger – CollectionTagger assigns one or more tags to the metadata of a document based on URL patterns defined in a JSON resource file. The resource file supports both include and exclude regular expressions:
{
"collections": [
{
"name": "stormcrawler",
"includePatterns": ["https://stormcrawler.net/.+"]
},
{
"name": "crawler",
"includePatterns": [".+crawler.+", ".+nutch.+"],
"excludePatterns": [".+baby.+", ".+spider.+"]
}
]
}-
CommaSeparatedToMultivaluedMetadata – CommaSeparatedToMultivaluedMetadata rewrites single metadata values containing comma-separated entries into multiple values for the same key, useful for keyword tags.
-
DebugParseFilter – DebugParseFilter dumps an XML representation of the DOM structure to a temporary file.
-
DomainParseFilter – DomainParseFilter stores the domain or host name in the metadata for later indexing.
-
LDJsonParseFilter – LDJsonParseFilter extracts data from JSON-LD representations.
-
LinkParseFilter – LinkParseFilter extracts outlinks from documents using XPath expressions defined in the configuration.
-
MD5SignatureParseFilter – MD5SignatureParseFilter generates an MD5 signature of a document based on the binary content, text, or URL (as a last resort). It can be combined with content filtering to exclude boilerplate text.
-
MimeTypeNormalization – MimeTypeNormalization converts server-reported or inferred mime-type values into human-readable values such as pdf, html, or image and stores them in the metadata, useful for indexing and filtering search results.
-
XPathFilter – XPathFilter allows extraction of data using XPath expressions and storing them in the Metadata object.
You can also implement custom ParseFilters to extend the capabilities of the parsing pipeline. For example, you might create a filter to enrich a document’s metadata with additional information, such as language detection, sentiment analysis, named entity recognition, or custom tags extracted from the content. Custom filters can also modify or remove outlinks, normalize text, or integrate external data sources, allowing you to tailor the crawler to your specific processing or indexing requirements. By implementing the ParseFilter interface and configuring the filter in the JSON file, your custom logic will be seamlessly executed within the parsing bolt.
5.6.2. URL Filters
The URL filters can be used to both remove or modify incoming URLs (unlike Nutch where these functionalities are separated between URLFilters and URLNormalizers). This is generally used within a parsing bolt to normalize and filter outgoing URLs, but is also called within the FetcherBolt to handle redirections.
URLFilters need to implement the interface URLFilter which defines a single method:
public String filter(URL sourceUrl, Metadata sourceMetadata,
String urlToFilter);and inherits a default one from Configurable:
public void configure(Map stormConf, JsonNode jsonNode);The configuration is done via a JSON file which is loaded by the wrapper class URLFilters. The URLFilter instances can be used directly, but it is easier to use the class URLFilters instead. Some filter implementations can also be configured with the standard configuration mechanism.
Here is an example of a JSON configuration file.
The JSON configuration allows loading several instances of the same filtering class with different parameters and can handle complex configuration objects since it makes no assumptions about the content of the field param. The URLFilters are executed in the order in which they are defined in the JSON file.
Built-in URL Filters
Basic
The BasicURLFilter filters based on the length of the URL and the repetition of path elements.
The BasicURLNormalizer removes the anchor part of URLs based on the value of the parameter removeAnchorPart. It also removes query elements based on the configuration and whether their value corresponds to a 32-bit hash.
FastURLFilter
The FastURLFilter is based on regex patterns and organized by scope (host | domain | metadata | global). For a given URL, the scopes are tried in the order given above and the URL is kept or removed based on the first matching rule. The default policy is to accept a URL if no match is found.
The resource file is in JSON and looks like this:
[{
"scope": "GLOBAL",
"patterns": [
"DenyPathQuery \\.jpg"
]
},
{
"scope": "domain:stormcrawler.net",
"patterns": [
"AllowPath /digitalpebble/",
"DenyPath .+"
]
},
{
"scope": "metadata:key=value",
"patterns": [
"DenyPath .+"
]
}]DenyPathQuery indicates that the pattern should be applied on the path URL path and the query element, whereas DenyPath means the path alone.
Host
The HostURLFilter filters URLs based on whether they belong to the same host or domain name as the source URL. This is configured with the parameters ignoreOutsideDomain and ignoreOutsideHost. The latter takes precedence over the former.
MaxDepth
The MaxDepthFilter is configured with the parameter maxDepth and requires metadata.track.depth to be set to true in the Configuration. This removes outlinks found too far from the seed URL and controls the expansion of the crawl.
If the filter is configured with a value of 0, all outlinks will be removed, regardless of whether the depth is being tracked.
The max depth can also be set on a per-seed basis using the key/value max.depth, which is automatically transferred to the outlinks if metadata.track.depth is set to true.
Metadata
The MetadataFilter filters URLs based on metadata in the source document.
RegexURLFilter
The RegexURLFilter uses a configuration file or a JSON ArrayNode containing regular expressions to determine whether a URL should be kept or not. The most specific rule must be placed first as a URL is kept or removed based on the first matching rule.
{
"urlFilters": [
"-^(file|ftp|mailto):",
"+."
]
}RegexURLNormalizer
The RegexURLNormalizer uses a configuration file or a JSON ArrayNode containing regular expressions and replacements to normalize URLs.
{
"urlNormalizers": [
{
"pattern": "#.*?(\\?|&|$)",
"substitution": "$1"
},
{
"pattern": "\\?&",
"substitution": "\\?"
}
]
}RobotsFilter
The RobotsFilter discards URLs based on the robots.txt directives. This is meant for small, limited crawls where the number of hosts is finite. Using this on a larger or open crawl would impact performance as the filter tries to retrieve the robots.txt files for any host found.
SelfURLFilter
The SelfURLFilter removes self-referential URLs, i.e., outlinks that point back to the same page they were discovered on (after normalization).
SitemapFilter
The SitemapFilter discards the outlinks of URLs which are not sitemaps when sitemaps have been found.
5.7. Metadata Transfer
The class MetadataTransfer is an important part of the framework and is used in key parts of a pipeline.
-
Fetching
-
Parsing
-
Updating bolts
An instance (or extension) of MetadataTransfer gets created and configured with the method public static MetadataTransfer getInstance(Map++<++String, Object++>++ conf) which takes the standard Apache Storm configuration as a parameter.
A MetadataTransfer instance has mainly two methods, both returning Metadata objects :
-
getMetaForOutlink(String targetUrl, String sourceUrl, Metadata parentMetadata) -
filter(Metadata metadata)
The former is used when creating Outlinks i.e. in the parsing bolts but also for handling redirections in the FetcherBolt(s) The latter is used by extensions of the AbstractStatusUpdaterBolt class to determine which Metadata should be persisted.
The behavior of the default MetadataTransfer class is driven by configuration only. It has the following options.
-
metadata.transferlist of metadata key values to filter or transfer to the outlinks. See crawler-default.yaml -
metadata.persistlist of metadata key values to persist in the status storage. See crawler-default.yaml -
metadata.track.pathwhether to track the URL path or not. Boolean value, true by default. -
metadata.track.depthwhether to track the depth from seed. Boolean value, true by default.
Note that the method getMetaForOutlink calls filter to determine what key values to keep.
5.8. Protocols
StormCrawler supports multiple network protocols for fetching content from various sources on the web. Each protocol implementation defines how the crawler connects to a resource, sends requests, and handles responses such as status codes, headers, and content streams.
Protocols are a key part of the fetching process and are used by StormCrawler’s bolts to retrieve data from remote servers.
While HTTP and HTTPS are the most commonly used, other protocols like file: are also supported for local or distributed filesystem access.
Use these configurations to fine-tune fetching performance, authentication, connection handling, and protocol-level optimizations across your crawler topology.
5.8.1. Following Redirects
When handling HTTP redirects, StormCrawler offers three modes:
-
Default behavior (
redirections.allowed: true,http.allow.redirects: false): The redirect target URL is emitted to the status stream. URL filter and normalization rules are applied to the target URL, the crawler verifies that the target URL is allowed perrobots.txt, and it is ensured that the redirect target is not fetched multiple times (URLs are deduplicated in the status index). -
Redirects disabled (
redirections.allowed: false): Redirect target URLs are not sent to the status stream. Redirects are effectively ignored. -
Immediate follow (
http.allow.redirects: true): Redirects are followed immediately in the HTTP client and the target URLs are not emitted to the status stream. This is the default behavior for browser-based protocols (Selenium and Playwright), but it is also supported by the OkHttp protocol. Note that with immediate follows, redirect targets bypass URL filtering, deduplication, androbots.txtchecks.
5.8.2. Network Protocols
The following network protocols are implemented in StormCrawler:
File
DelegatorProtocol
The DelegatorProtocol enables selection from a collection of sub-protocols using filters based on metadata and URL patterns. The last protocol in the list acts as the default. This is useful when certain URLs need to be fetched with a browser-based protocol (e.g., Selenium) while the majority use a standard HTTP client.
http.protocol.implementation: "org.apache.stormcrawler.protocol.DelegatorProtocol"
protocol.delegator.config:
- className: "org.apache.stormcrawler.protocol.httpclient.HttpProtocol"
filters:
domain: "example.com"
- className: "org.apache.stormcrawler.protocol.okhttp.HttpProtocol"The protocols are tried in order; the first matching filter wins. Filters can match on metadata keys, domain names, or URL regex patterns.
HTTP/S
See [Metadata-dependent Behavior For HTTP Protocols] for the effect of metadata content on protocol behaviour.
To change the implementation, add the following lines to your custom configuration YAML file:
http.protocol.implementation: "org.apache.stormcrawler.protocol.okhttp.HttpProtocol"
https.protocol.implementation: "org.apache.stormcrawler.protocol.okhttp.HttpProtocol"5.8.3. Feature grid
| Features | HTTPClient | OKHttp | Selenium |
|---|---|---|---|
Basic authentication |
N |
||
Proxy (w. credentials?) |
Y / Y |
Y / Y |
? |
Interruptible / trimmable #463 |
N / Y |
Y / Y |
Y / N |
Cookies |
Y |
N |
|
Response headers |
Y |
Y |
N |
Trust all certificates |
N |
N |
|
HEAD method |
N |
||
POST method |
N |
N |
|
Verbatim response header |
N |
||
Verbatim request header |
N |
N |
|
IP address capture |
N |
N |
|
Navigation and javascript |
N |
N |
Y |
HTTP/2 |
N |
Y |
(Y) |
Configurable connection pool |
N |
N |
5.8.4. HTTP/2
-
The OKHttp protocol supports HTTP/2 if the JDK includes ALPN (Java 9 and upwards or Java 8 builds starting early/mid 2020).
-
HttpClient does not yet support HTTP/2.
-
Selenium: whether HTTP/2 is used or not depends on the used driver.
Since #829, the HTTP protocol version used is configurable via http.protocol.versions (see also comments in crawler-default.yaml).
For example, to force that only HTTP/1.1 is used:
http.protocol.versions:
- "http/1.1"5.8.5. Metadata-dependent Behavior For HTTP Protocols
The metadata argument to HTTPProtocol.getProtocolOutput() can affect the behavior of the protocol. The following metadata keys are detected by HTTPProtocol implementations and utilized in performing the request:
-
last-modified: If this key is present inmetadata, the protocol will use the metadata value as the date for theIf-Modified-Sinceheader field of the HTTP request. If the key is not present, theIf-Modified-Sincefield won’t be added to the request header. -
protocol.etag: If this key is present inmetadata, the protocol will use the metadata value as the ETag for theIf-None-Matchheader field of the HTTP request. If the key is not present, theIf-None-Matchfield won’t be added to the request header. -
http.accept: If this key is present inmetadata, the protocol will use the value to override the value for theAcceptheader field of the HTTP request. If the key is not present, thehttp.acceptglobal configuration value is used instead. (Available in v1.11+) -
http.accept.language: If this key is present inmetadata, the protocol will use the value to override the value for theAccept-Languageheader field of the HTTP request. If the key is not present, thehttp.accept.languageglobal configuration value is used instead. (Available in v1.11+) -
protocol.set-cookie: If this key is present inmetadataandhttp.use.cookiesis true, the protocol will send cookies stored from the response this page was linked to, given the cookie is applicable to the domain of the link. -
http.method.head: If this key is present inmetadata, the protocol sends a HEAD request. (Available in v1.12+ only for httpclient, see #485) -
http.post.json: If this key is present inmetadata, the protocol sends a POST request. (Available in v1.12+ only for okhttp, see #641) -
protocol.set-headers: If this key is present in metadata, the protocol adds the specified headers to the request. See #993
Example:
"protocol%2Eset-header": [
"header1=value1",
"header2=value2"
]Notes:
-
Metadata values starting with
protocol.may start with a different prefix instead. Seeprotocol.md.prefixand #776. -
Metadata used for requests needs to be persisted. For example:
metadata.persist:
- last-modified
- protocol.etag
- protocol.set-cookie
- ...-
Cookies need to be transferred to outlinks by setting:
metadata.transfer:
- set-cookie6. Configuration
6.1. User Agent Configuration
Crawlers should always act responsibly and ethically when accessing websites. A key aspect of this is properly identifying themselves through the User-Agent header. By providing a clear and accurate user agent string, webmasters can understand who is visiting their site and why, and can apply rules in robots.txt accordingly. Respecting these rules, avoiding excessive request rates, and honoring content restrictions not only ensures legal compliance but also maintains a healthy relationship with the web community.
Transparent identification is a fundamental part of ethical web crawling.
The configuration of the user agent in StormCrawler has two purposes:
-
Identification of the crawler for webmasters
-
Selection of rules from robots.txt
6.1.1. Crawler Identification
The politeness of a web crawler is not limited to how frequently it fetches pages from a site, but also in how it identifies itself to sites it crawls. This is done by setting the HTTP header User-Agent, just like your web browser does.
The full user agent string is built from the concatenation of the configuration elements:
-
http.agent.name: name of your crawler -
http.agent.version: version of your crawler -
http.agent.description: description of what it does -
http.agent.url: URL webmasters can go to to learn about it -
http.agent.email: an email so that they can get in touch with you
Whereas StormCrawler used to provide a default value for these, this is not the case since version 2.11 and you will now be asked to provide a value.
You can specify the user agent verbatim with the config http.agent but you will still need to provide a http.agent.name for parsing robots.txt files.
6.1.2. Robots Exclusion Protocol
This is also known as the robots.txt protocol, it is formalised in RFC 9309. Part of what the robots directives do is to define rules to specify which parts of a website (if any) are allowed to be crawled. The rules are organised by User-Agent, with a * to match any agent not otherwise specified explicitly, e.g.:
User-Agent: * Disallow: *.gif$ Disallow: /example/ Allow: /publications/
In the example above the rule allows access to the URLs with the /publications/ path prefix, and it restricts access to the URLs with the /example/ path prefix and to all URLs with a .gif suffix. The "*" character designates any character, including the otherwise-required forward slash.
The value of http.agent.name is what StormCrawler looks for in the robots.txt. It MUST contain only uppercase and lowercase letters ("a-z" and "A-Z"), underscores ("_"), and hyphens ("-").
Unless you are running a well known web crawler, it is unlikely that its agent name will be listed explicitly in the robots.txt (if it is, well, congratulations!). While you want the agent name value to reflect who your crawler is, you might want to follow rules set for better known crawlers. For instance, if you were a responsible AI company crawling the web to build a dataset to train LLMs, you would want to follow the rules set for Google-Extended (see list of Google crawlers) if any were found.
This is what the configuration http.robots.agents allows you to do. It is a comma-separated string but can also take a list of values. By setting it alongside http.agent.name (which should also be the first value it contains), you are able to broaden the match rules based on the identity as well as the purpose of your crawler.
6.2. Proxy
StormCrawler’s proxy system is built on top of the SCProxy class and the ProxyManager interface. Every proxy used in the system is formatted as a SCProxy. The ProxyManager implementations handle the management and delegation of their internal proxies. At the call of Protocol#getProtocolOutput(), the ProxyManager.getProxy() is called to retrieve a proxy for the individual request.
The ProxyManager interface can be implemented in a custom class to create custom logic for proxy management and load balancing. The default ProxyManager implementation is SingleProxyManager. This ensures backwards compatibility for prior StormCrawler releases. To use MultiProxyManager or custom implementations, pass the class path and name via the config parameter http.proxy.manager:
http.proxy.manager: "org.apache.stormcrawler.proxy.MultiProxyManager"
StormCrawler implements two ProxyManager classes by default:
-
SingleProxyManager Manages a single proxy passed by the backwards compatible proxy fields in the configuration:
---- http.proxy.host http.proxy.port http.proxy.type http.proxy.user (optional) http.proxy.pass (optional) ----
-
MultiProxyManager Manages multiple proxies passed through a TXT file. The file should contain connection strings for all proxies including the protocol and authentication (if needed). The file supports comment lines (
//or#) and empty lines. The file path should be passed via the config at the below field. The TXT file must be available to all nodes participating in the topology:---- http.proxy.file ----
The MultiProxyManager load balances across proxies using one of the following schemes. The load balancing scheme can be passed via the config using http.proxy.rotation; the default value is ROUND_ROBIN:
-
ROUND_ROBIN Evenly distributes load across all proxies
-
RANDOM Randomly selects proxies using the native Java random number generator. RNG is seeded with the nanos at instantiation
-
LEAST_USED Selects the proxy with the least amount of usage. This is performed lazily for speed and therefore will not account for changes to usages during the selection process. If no custom implementations are made this should theoretically operate the same as ROUND_ROBIN
The SCProxy class contains all of the information associated with proxy connection. In addition, it tracks the total usage of the proxy and optionally tracks the location of the proxy IP. Usage information is used for the LEAST_USED load balancing scheme. The location information is currently unused but left to enable custom implementations the ability to select proxies by location.
6.3. Metadata
6.3.1. Registering Metadata for Kryo Serialization
If your Apache StormCrawler topology doesn’t extend org.apache.stormcrawler.ConfigurableTopology, you will need to manually register StormCrawler’s Metadata class for serialization in Storm. For more information on Kryo serialization in Apache Storm, you can refer to the documentation.
To register Metadata for serialization, you’ll need to import org.apache.storm.Config and org.apache.stormcrawler.Metadata. Then, in your topology class, you’ll register the class with:
Config.registerSerialization(conf, Metadata.class);where conf is your Storm configuration for the topology.
Alternatively, you can specify in the configuration file:
topology.kryo.register:
- org.apache.stormcrawler.Metadata6.3.2. MetadataTransfer
The class MetadataTransfer is an important part of the framework and is used in key parts of a pipeline:
-
Fetching
-
Parsing
-
Updating bolts
An instance (or extension) of MetadataTransfer gets created and configured with the method:
public static MetadataTransfer getInstance(Map<String, Object> conf)A MetadataTransfer instance has mainly two methods, both returning Metadata objects:
-
getMetaForOutlink(String targetURL, String sourceURL, Metadata parentMD) -
filter(Metadata metadata)
The former is used when creating Outlinks, i.e., in the parsing bolts but also for handling redirections in the [[FetcherBolt(s)]].
The latter is used by extensions of the AbstractStatusUpdaterBolt class to determine which Metadata should be persisted.
The behavior of the default MetadataTransfer class is driven by configuration only. It has the following options:
-
metadata.transfer:: list of metadata key values to filter or transfer to the outlinks. Please see the corresponding comments in crawler-default.yaml -
metadata.persist:: list of metadata key values to persist in the status storage. Please see the corresponding comments in crawler-default.yaml -
metadata.track.path:: whether to track the URL path or not. Boolean value, true by default. -
metadata.track.depth:: whether to track the depth from seed. Boolean value, true by default.
Note that the method getMetaForOutlink calls filter to determine which key values to keep.
6.4. Configuration Options
The following tables describe all available configuration options and their default values. If one of the keys is not present in your YAML file, the default value will be taken.
Note: Some configuration options may not be applicable depending on the specific components and features you are using in your Apache StormCrawler topology. Some external modules might define additional options not listed here.
6.4.1. Fetching and Partitioning
| key | default value | description |
|---|---|---|
fetcher.max.crawl.delay |
30 |
Maximum accepted Crawl-delay from robots.txt (seconds). If the crawl-delay exceeds this value the behavior depends on the value of fetcher.max.crawl.delay.force. |
fetcher.max.crawl.delay.force |
false |
Configures the behavior of fetcher if the robots.txt crawl-delay exceeds fetcher.max.crawl.delay. If false: the tuple is emitted to the StatusStream as an ERROR. If true: the queue delay is set to fetcher.max.crawl.delay. |
fetcher.max.queue.size |
-1 |
The maximum length of the queue used to store items to be fetched by the FetcherBolt. A setting of -1 sets the length to Integer.MAX_VALUE. |
fetcher.max.throttle.sleep |
-1 |
The maximum amount of time to wait between fetches; if exceeded, the item is sent to the back of the queue. Used in SimpleFetcherBolt. -1 disables it. |
fetcher.max.urls.in.queues |
-1 |
Limits the number of URLs that can be stored in a fetch queue. -1 disables the limit. |
fetcher.maxThreads.host/domain/ip |
fetcher.threads.per.queue |
Overwrites fetcher.threads.per.queue. Useful for crawling some domains/hosts/IPs more intensively. |
fetcher.metrics.time.bucket.secs |
10 |
Metrics events emitted every value seconds to the system stream. |
fetcher.queue.mode |
byHost |
Possible values: byHost, byDomain, byIP. Determines queue grouping. |
fetcher.server.delay |
1 |
Delay between crawls in the same queue if no Crawl-delay is defined. |
fetcher.server.delay.force |
false |
Defines fetcher behavior when the robots.txt crawl-delay is smaller than fetcher.server.delay. |
fetcher.server.min.delay |
0 |
Delay between crawls for queues with >1 thread. Ignores robots.txt. |
fetcher.threads.number |
10 |
Total concurrent threads fetching pages. Adjust carefully based on system capacity. |
fetcher.threads.per.queue |
1 |
Default number of threads per queue. Can be overridden. |
fetcher.threads.start.delay |
10 |
Delay (milliseconds) between starting next fetcher thread. Avoids overloading DNS or network resources during fetcher startup when all threads simultaneously start requesting pages. |
fetcher.timeout.queue |
-1 |
Maximum wait time (seconds) for items in the queue. -1 disables timeout. |
fetcherbolt.queue.debug.filepath |
"" |
Path to a debug log (e.g. /tmp/fetcher-dump-{port}). |
http.agent.description |
- |
Description for the User-Agent header. |
http.agent.email |
- |
Email address in User-Agent header. |
http.agent.name |
- |
Name in User-Agent header. |
http.agent.url |
- |
URL in User-Agent header. |
http.agent.version |
- |
Version in User-Agent header. |
http.basicauth.password |
- |
Password for http.basicauth.user. |
http.basicauth.user |
- |
Username for Basic Authentication. |
http.content.limit |
-1 |
Maximum HTTP response body size (bytes). Default: no limit. |
http.protocol.implementation |
org.apache.stormcrawler.protocol.httpclient.HttpProtocol |
HTTP Protocol implementation. |
http.proxy.host |
- |
HTTP proxy host. |
http.proxy.pass |
- |
Proxy password. |
http.proxy.port |
8080 |
Proxy port. |
http.proxy.user |
- |
Proxy username. |
http.retry.on.connection.failure |
true |
(OkHttp only) Retry fetching on connection failure. See OkHttp docs. |
http.robots.403.allow |
true |
Allow crawling when robots.txt returns HTTP 403. |
http.robots.5xx.allow |
false |
Allow crawling when robots.txt returns a server error (5xx). |
http.robots.agents |
'' |
Additional user-agent strings for interpreting robots.txt. |
http.robots.content.limit |
-1 |
Maximum bytes to fetch for robots.txt. -1 uses http.content.limit. |
http.robots.file.skip |
false |
Ignore robots.txt rules entirely. |
http.robots.headers.skip |
false |
Ignore robots directives from HTTP headers. |
http.robots.meta.skip |
false |
Ignore robots directives from HTML meta tags. |
http.skip.robots |
false |
Deprecated (replaced by http.robots.file.skip). |
robots.noFollow.strict |
true |
If true, remove all outlinks from pages marked as noFollow. |
http.store.headers |
false |
Whether to store response headers. |
http.timeout |
10000 |
Connection timeout (ms). |
http.use.cookies |
false |
Use cookies in subsequent requests. |
https.protocol.implementation |
org.apache.stormcrawler.protocol.httpclient.HttpProtocol |
HTTPS Protocol implementation. |
partition.url.mode |
byHost |
Defines how URLs are partitioned: byHost, byDomain, or byIP. |
protocols |
http,https,file |
Supported protocols. |
redirections.allowed |
true |
If true, emit redirect target URLs as "outlinks" to the status stream. If false, do not follow redirects. See also |
http.allow.redirects |
false |
(OkHttp only) Follow HTTP redirects immediately in the HTTP protocol client. Note: if followed immediately, redirect target URLs are not emitted to the status stream, are not filtered, not deduplicated, and not checked against robots.txt. |
sitemap.discovery |
false |
Enable automatic sitemap discovery. |
urlbuffer.class |
org.apache.stormcrawler.persistence.urlbuffer.SimpleURLBuffer |
URL buffer implementation used by spouts. |
6.4.2. Protocol
| key | default value | description |
|---|---|---|
file.protocol.implementation |
org.apache.stormcrawler.protocol.file.FileProtocol |
Protocol implementation for file:// URLs. |
file.encoding |
UTF-8 |
Encoding for FileProtocol. |
protocol.instances.num |
1 |
Number of instances per protocol implementation. |
http.protocol.versions |
- |
HTTP protocol versions in order of preference (h2, http/1.1, http/1.0, h2c). If empty, uses implementation defaults. |
robots.cache.spec |
maximumSize=10000,expireAfterWrite=6h |
CacheBuilder configuration for robots cache. |
robots.error.cache.spec |
maximumSize=10000,expireAfterWrite=1h |
CacheBuilder configuration for error cache. |
okhttp.protocol.connection.pool.max.idle.connections |
5 |
OkHttp maximum number of idle connections. |
okhttp.protocol.connection.pool.connection.keep.alive |
300 |
OkHttp connection keep-alive time (seconds). |
http.custom.headers |
- |
Custom HTTP headers. |
http.accept |
text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8 |
HTTP Accept header. |
http.accept.language |
en-us,en-gb,en;q=0.7,*;q=0.3 |
HTTP Accept-Language header. |
http.content.partial.as.trimmed |
false |
Accepts partially fetched content in OKHTTP. |
http.trust.everything |
true |
If true, trust all SSL/TLS connections. |
navigationfilters.config.file |
- |
JSON config for NavigationFilter (used by the Selenium protocol module). |
selenium.addresses |
- |
WebDriver server addresses. |
selenium.capabilities |
- |
Desired WebDriver capabilities . |
selenium.delegated.protocol |
- |
Delegated protocol for selective Selenium usage. |
selenium.implicitlyWait |
0 |
WebDriver element search timeout. |
selenium.instances.num |
1 |
Number of instances per WebDriver connection. |
selenium.pageLoadTimeout |
0 |
WebDriver page load timeout. |
selenium.setScriptTimeout |
0 |
WebDriver script execution timeout. |
topology.message.timeout.secs |
-1 |
OKHTTP message timeout. |
6.4.3. Indexing
The values below are used by sub-classes of AbstractIndexerBolt.
| key | default value | description |
|---|---|---|
indexer.canonical.name |
canonical |
Metadata key for the canonical URL. Used to replace the URL with its canonical form before indexing. |
indexer.ignore.empty.fields |
false |
If true, skip fields with empty values when indexing. |
indexer.md.filter |
- |
YAML list of key=value filters for metadata-based indexing. |
indexer.md.mapping |
- |
YAML mapping from metadata fields to persistence layer fields. |
indexer.text.fieldname |
content |
Field name for indexed HTML body text. |
indexer.text.maxlength |
-1 |
Maximum length of text to index. -1 means no limit. |
indexer.url.fieldname |
url |
Field name for indexed URL. |
6.4.4. Status Persistence
This refers to persisting the status of a URL (e.g. ERROR, DISCOVERED etc.) along with something like a nextFetchDate
that is being calculated by a Scheduler.
| key | default value | description |
|---|---|---|
fetchInterval.default |
1440 |
Default revisit interval (minutes). Used by DefaultScheduler. |
fetchInterval.error |
-1 |
Revisit interval for error pages (minutes). -1 means never refetch. |
fetchInterval.fetch.error |
120 |
Revisit interval for fetch errors (minutes). |
max.fetch.errors |
3 |
Maximum number of successive fetch errors before changing status to ERROR. |
scheduler.class |
org.apache.stormcrawler.persistence.DefaultScheduler |
Scheduler implementation for computing next fetch dates. Use AdaptiveScheduler for change-rate-based intervals. |
status.updater.cache.spec |
maximumSize=10000, expireAfterAccess=1h |
Cache specification for the status updater. |
status.updater.unit.round.date |
SECOND |
Unit for rounding the next fetch date. Can also be MINUTE or HOUR. |
status.updater.use.cache |
true |
Whether to use cache to avoid re-persisting URLs. |
6.4.5. Parsing
Configures parsing of fetched text and the handling of discovered URIs
| key | default value | description |
|---|---|---|
collections.file |
collections.json |
Config for CollectionTagger. |
collections.key |
collections |
Key under which tags are stored in metadata. |
detect.charset.maxlength |
10000 |
Maximum number of bytes used for charset detection. |
detect.mimetype |
true |
Enable MIME type detection during parsing. |
feed.filter.hours.since.published |
-1 |
Discard feeds older than value hours. |
feed.sniffContent |
false |
Try to detect feeds automatically. |
jsoup.treat.non.html.as.error |
true |
If true, non-HTML content is treated as an error by JSoupParserBolt. |
parsefilters.config.file |
parsefilters.json |
Path to JSON config defining ParseFilters. See default parsefilters.json. |
parser.emitOutlinks |
true |
Emit discovered links as DISCOVERED tuples. |
parser.emitOutlinks.max.per.page |
-1 |
Limit number of emitted links per page. |
sitemap.filter.hours.since.modified |
-1 |
Filter URLs in sitemaps based on their modification date. -1 disables filtering. |
sitemap.schedule.delay |
-1 |
Staggered scheduling delay for sitemaps (minutes). -1 disables staggering. |
sitemap.extensions |
- |
Sitemap extensions to parse (IMAGE, LINKS, MOBILE, NEWS, VIDEO). |
textextractor.exclude.tags |
"" |
HTML tags ignored by TextExtractor. |
textextractor.include.pattern |
"" |
Regex patterns to include for TextExtractor. |
textextractor.no.text |
false |
Disable text extraction entirely. |
textextractor.skip.after |
-1 |
Stop text extraction after this many characters. -1 means no limit. |
track.anchors |
true |
Add anchor text to outlink metadata. |
urlfilters.config.file |
urlfilters.json |
JSON file defining URL filters. See default urlfilters.json. |
6.4.6. Metadata
Options on how Storm Crawler should handle metadata tracking as well as minimising metadata clashes
| key | default value | description |
|---|---|---|
metadata.persist |
- |
Metadata to persist but not transfer to outlinks. |
metadata.track.depth |
true |
Track crawl depth of URLs. |
metadata.track.path |
true |
Track URL path history in metadata. |
metadata.transfer |
- |
Metadata to transfer to outlinks. |
metadata.transfer.class |
org.apache.stormcrawler.util.MetadataTransfer |
Class handling metadata transfer. |
protocol.md.prefix |
protocol. |
Prefix for remote metadata keys to avoid collisions. |
6.5. External Module Configuration
The following sections document configuration options for the external integration modules. Each module has its own Maven dependency and may require additional infrastructure (e.g., OpenSearch, Solr, a SQL database). For full setup instructions, see the README in each module’s directory.
6.5.1. OpenSearch
Integration with OpenSearch for indexing, URL status persistence, and metrics. See the opensearch module for full details.
| key | default value | description |
|---|---|---|
opensearch.addresses |
- |
OpenSearch server address(es). |
opensearch.user |
- |
Username for authentication (optional). |
opensearch.password |
- |
Password for authentication (optional). |
opensearch.concurrentRequests |
2 |
Number of concurrent bulk requests. |
opensearch.indexer.index.name |
content |
Index name for crawled documents. |
opensearch.indexer.create |
false |
Auto-create index if it does not exist. |
opensearch.indexer.bulkActions |
100 |
Number of documents to buffer before flushing. |
opensearch.indexer.flushInterval |
2s |
Maximum time before flushing the bulk buffer. |
opensearch.indexer.pipeline |
- |
Ingest pipeline name (optional). |
opensearch.status.index.name |
status |
Index name for URL status. |
opensearch.status.bulkActions |
500 |
Batch size for status updates. |
opensearch.status.flushInterval |
5s |
Flush interval for status updates. |
opensearch.status.routing |
true |
Enable index routing for status documents. |
opensearch.status.routing.fieldname |
key |
Field used for routing. |
opensearch.status.max.buckets |
50 |
Number of buckets for AggregationSpout. |
opensearch.status.max.urls.per.bucket |
2 |
URLs returned per bucket. |
opensearch.status.bucket.field |
key |
Field used for bucketing. |
opensearch.status.sample |
false |
Use random sampling in AggregationSpout. |
opensearch.metrics.index.name |
metrics |
Index name for Storm metrics. |
6.5.2. Solr
Integration with Apache Solr for indexing, URL status persistence, and metrics. See the solr module for full details. Supports both standalone Solr and SolrCloud (via ZooKeeper).
| key | default value | description |
|---|---|---|
solr.indexer.url |
- |
Solr collection URL for indexing. |
solr.indexer.zkhost |
- |
ZooKeeper host for SolrCloud indexing (alternative to URL). |
solr.indexer.collection |
- |
SolrCloud collection name for indexing. |
solr.status.url |
- |
Solr collection URL for status storage. |
solr.status.zkhost |
- |
ZooKeeper host for SolrCloud status (alternative to URL). |
solr.status.collection |
- |
SolrCloud collection name for status. |
solr.status.bucket.field |
host |
Field used for bucketing in SolrSpout. |
solr.status.bucket.maxsize |
5 |
Maximum URLs per bucket. |
solr.status.max.results |
10 |
Maximum results per spout query. |
solr.status.metadata.prefix |
metadata |
Prefix for metadata fields in Solr. |
solr.metrics.url |
- |
Solr collection URL for metrics. |
6.5.3. SQL
Integration with relational databases via JDBC for URL status persistence, indexing, and metrics. See the sql module for full details and table creation scripts.
| key | default value | description |
|---|---|---|
sql.connection.url |
- |
JDBC connection URL. |
sql.connection.user |
- |
Database username. |
sql.connection.password |
- |
Database password. |
sql.status.table |
urls |
Table name for URL status storage. |
sql.max.urls.per.bucket |
5 |
Maximum URLs per bucket in SQLSpout. |
sql.spout.max.results |
100 |
Maximum results per spout query. |
sql.metrics.table |
metrics |
Table name for metrics storage. |
sql.index.table |
content |
Table name for indexed content. |
6.5.4. URLFrontier
Integration with URLFrontier, a language-agnostic API for URL management and scheduling. See the urlfrontier module for full details.
| key | default value | description |
|---|---|---|
urlfrontier.host |
localhost |
URLFrontier service hostname. |
urlfrontier.port |
7071 |
URLFrontier service port. |
urlfrontier.max.buckets |
10 |
Number of buckets to request from the frontier. |
urlfrontier.max.urls.per.bucket |
10 |
Maximum URLs per bucket. |
6.5.5. Tika
Apache Tika integration for parsing non-HTML documents (PDF, Word, etc.). See the tika module for full details.
| key | default value | description |
|---|---|---|
parser.mimetype.whitelist |
- |
Regex list of allowed MIME types. If set, only matching types are parsed by the Tika ParserBolt. |
parser.tika.config.file |
tika-config.xml |
Path to the Tika configuration XML file. |
When using the Tika ParserBolt alongside JSoupParserBolt, set jsoup.treat.non.html.as.error to false so that non-HTML content is passed through to the Tika parser rather than being treated as an error.
|
6.5.6. AWS
Integration with AWS services: CloudSearch for indexing and S3 for content caching. See the aws module for full details.
| key | default value | description |
|---|---|---|
cloudsearch.endpoint |
- |
AWS CloudSearch document endpoint URL. |
cloudsearch.region |
- |
AWS region (e.g., "eu-west-1"). |
cloudsearch.batch.maxSize |
-1 |
Documents to buffer before sending a batch. -1 disables batching. |
cloudsearch.batch.max.time.buffered |
10 |
Maximum time (seconds) before flushing the buffer. |
cloudsearch.batch.dump |
false |
Dump batch JSON to a temp directory for debugging. |
s3.region |
- |
AWS region for S3 operations. |
s3.bucket |
- |
S3 bucket name for content caching. |
s3.endpoint |
- |
Custom S3 endpoint (optional, for S3-compatible services). |
6.5.7. AI (LLM Text Extraction)
LLM-based text extraction using OpenAI-compatible APIs (including local models via Ollama). See the ai module for full details.
| key | default value | description |
|---|---|---|
textextractor.class |
- |
Set to |
textextractor.llm.api_key |
- |
API key for the LLM service. |
textextractor.llm.url |
- |
LLM API endpoint URL (e.g., OpenAI or Ollama endpoint). |
textextractor.llm.model |
- |
Model name to use (e.g., "gpt-4", "llama2"). |
textextractor.system.prompt |
- |
System prompt for the LLM (optional). |
textextractor.llm.prompt |
- |
User prompt template. Use |
textextractor.llm.user_request |
- |
Extra user request passed to the prompt template (optional). |
textextractor.llm.listener.clazz |
- |
Listener class for tracking LLM response metrics (optional). |
6.5.8. Playwright
Browser-based fetching using Playwright for JavaScript-rendered pages. See the playwright module for full details.
| key | default value | description |
|---|---|---|
playwright.cdp.url |
- |
Chrome DevTools Protocol URL for connecting to an existing browser instance (e.g. |
playwright.remote.ws |
- |
Remote WebSocket URL for Playwright (alternative to CDP, e.g. |
playwright.skip.download |
false |
Skip automatic browser download. Implicitly forced to |
playwright.load.event |
load |
Page load event to wait for. One of |
playwright.skip.resource.types |
- |
List of resource types aborted during navigation ( |
playwright.evaluations |
- |
List of JavaScript expressions evaluated after load; each JSON-serialised result is stored in response metadata under the expression itself. |
playwright.capture.content.on.error |
false |
If |
playwright.override.status.on.content |
false |
When content was captured for a non-2xx response, override the reported HTTP status with |
playwright.page.actions.config.file |
- |
JSON file declaring an ordered chain of |
Page actions
The Playwright protocol exposes a PageAction extension point — an ordered chain of post-navigate
DOM transformations loaded from a JSON file referenced by playwright.page.actions.config.file. Use
this to plug site-specific behaviour (tab/accordion expansion, cookie-banner dismissal,
infinite-scroll, custom evaluate() calls, screenshotting, …) into the protocol without
subclassing it. The chain runs only when content would otherwise be captured (on 2xx, or on non-2xx
when playwright.capture.content.on.error is true). Per-action failures are logged and swallowed
so one bad action cannot abort the rest of the chain.
{
"org.apache.stormcrawler.protocol.playwright.PageActions": [
{
"class": "org.apache.stormcrawler.protocol.playwright.actions.DismissOverlayAction",
"name": "cookies",
"params": { "selectors": ["#cookie-accept"] }
},
{
"class": "org.apache.stormcrawler.protocol.playwright.actions.ExpandClickablesAction",
"name": "tabs",
"params": {
"selectors": [".tab-widget .tab-header"],
"root": ".tab-widget",
"body": ".tab-widget-body",
"waitMs": 300
}
}
]
}Built-in actions:
| Class | Purpose |
|---|---|
|
Clicks every element matching the configured selectors and clones the resulting body container into a hidden cache under the same widget root, so |
|
Evaluates a list of JavaScript expressions and stores each JSON-serialised result in response metadata. |
|
Repeatedly scrolls to the bottom of the page until the document height stops growing, the step cap is reached, or the time budget elapses — useful for infinite-scroll feeds. |
|
Waits for a selector to reach an |
|
Dismisses cookie banners, GDPR walls, newsletter modals, etc. by clicking the first match of each selector, and optionally removes sticky overlays from the DOM via |
|
Captures a screenshot of the page and stores it base64-encoded in response metadata. For diagnostics / small-volume use; larger crawls should write to a blob store. |
See the playwright module README for the full parameter list of each built-in action and a guide on writing your own.
JS rendering detection
Browser fetching is much more expensive than a plain HTTP fetch, so most operators only want
Playwright on URLs that actually need it. The JsRenderingDetector parse filter inspects the
parsed page from a cheap fetch and sets a metadata flag (default fetch.with=playwright) on URLs
that look JavaScript-rendered. Pair it with DelegatorProtocol
to route subsequent fetches of those URLs to the Playwright protocol while leaving everything else
on a fast HTTP client.
Detection signals (cheapest first, short-circuiting):
-
SPA framework fingerprints in raw HTML —
data-reactroot,ng-version=,__NEXT_DATA__,window.__NUXT__,data-svelte-h=,data-vue-app,data-astro-cid,<router-outlet. -
<noscript>blocks containing language like "enable JavaScript". -
Empty SPA hydration roots:
<div id="root"></div>/#app/#__next/#__nuxt. -
Outcome-based fallback: at least one
<script>is present and bothtext.lengthand the outlink count are below configurable thresholds.
Detection is skipped when playwright.protocol.end is already on the URL (i.e. it was just
fetched by Playwright) or when the routing key is already set, so the filter is idempotent.
Register the filter in parsefilters.json:
{
"class": "org.apache.stormcrawler.protocol.playwright.parsefilter.JsRenderingDetector",
"name": "js-rendering-detector",
"params": { "minTextLength": 200, "minOutlinks": 2 }
}And route on the metadata key it sets:
http.protocol.implementation: "org.apache.stormcrawler.protocol.DelegatorProtocol"
https.protocol.implementation: "org.apache.stormcrawler.protocol.DelegatorProtocol"
protocol.delegator.config:
- className: "org.apache.stormcrawler.protocol.playwright.HttpProtocol"
filters:
"fetch.with": "playwright"
- className: "org.apache.stormcrawler.protocol.okhttp.HttpProtocol"The dotted metadata key is quoted in the YAML above for readability; SnakeYAML accepts the
unquoted form too. Note that DelegatorProtocol requires the last entry in
protocol.delegator.config to have no filters: — it acts as the fallback, so keep the cheap
protocol at the bottom of the list.
The parse filter alone does not trigger an immediate refetch — it only sets the metadata flag
on the current fetch, and DefaultScheduler reschedules the URL according to the FETCHED interval
(fetchInterval.default, 24h by default). For faster turnaround, either add a per-metadata-key
fetch interval (fetchInterval.fetch.with=playwright: 5) or drop JsRenderingRedirectionBolt
between the parser and indexer. The bolt reads the routing flag and, on hit, emits only to the
status stream with Status.FETCHED so the stub document never reaches the index. The full
parameter list and tuning notes are in the playwright module README.
6.5.9. Language ID
Language identification for crawled documents using the lang-detect library. See the langid module source code for details.
The LanguageID parse filter is configured in parsefilters.json:
{
"class": "org.apache.stormcrawler.parse.filter.LanguageID",
"name": "LanguageID",
"params": {
"key": "lang",
"minProb": 0.99,
"extracted": "parse.lang"
}
}-
key— metadata key to store the detected language code (default: "lang") -
minProb— minimum probability threshold for detection (default: 0.999) -
extracted— metadata key to check for a pre-extracted language value (default: "parse.lang")
6.5.10. WARC
Reading and writing WARC (Web ARChive) files for archival and replay. See the warc module for full details.
| key | default value | description |
|---|---|---|
warc.metadata.keys |
- |
Metadata keys to include as WARC metadata records (optional list). |
For complete WARC records, set http.store.headers to true. The OkHttp protocol (org.apache.stormcrawler.protocol.okhttp.HttpProtocol) is recommended for WARC generation as it provides verbatim HTTP headers.
|
6.5.11. Common Spout Configuration
The following options are shared across storage-backed spouts (OpenSearch, Solr, SQL) that extend AbstractQueryingSpout:
| key | default value | description |
|---|---|---|
spout.ttl.purgatory |
30 |
Time (seconds) a URL remains in purgatory after ack/fail before it can be re-emitted. |
spout.min.delay.queries |
2000 |
Minimum delay (ms) between backend queries. |
spout.max.delay.queries |
20000 |
Maximum delay (ms) between backend queries (OpenSearch only). |
spout.reset.fetchdate.after |
120 |
Reset a URL’s fetch date if it has not been acked within this many seconds. |
7. Extending and Operating StormCrawler
This section provides practical guides for extending StormCrawler with custom components, tuning crawl performance, and operating crawlers in production.
7.1. Writing Custom Components
7.1.1. Custom URL Filter
URL filters accept, reject, or modify URLs during parsing and redirection handling. To create a custom filter, extend the abstract URLFilter class and implement the filter method.
import org.apache.stormcrawler.filtering.URLFilter;
import org.apache.stormcrawler.Metadata;
import com.fasterxml.jackson.databind.JsonNode;
import java.net.URL;
import java.util.Map;
public class MyURLFilter extends URLFilter {
private int maxLength;
@Override
public void configure(Map<String, Object> stormConf, JsonNode paramNode) {
maxLength = paramNode.path("maxLength").asInt(1024);
}
@Override
public String filter(URL sourceUrl, Metadata sourceMetadata, String urlToFilter) {
if (urlToFilter.length() > maxLength) {
return null; // reject
}
return urlToFilter; // accept (or return a normalized version)
}
}Register the filter in urlfilters.json:
{
"org.apache.stormcrawler.filtering.URLFilters": [
{
"class": "com.example.MyURLFilter",
"name": "MyURLFilter",
"params": {
"maxLength": 2048
}
}
]
}Filters are executed in the order they appear in the JSON file. Return null to reject a URL, or return the (possibly modified) URL string to accept it.
7.1.2. Custom Parse Filter
Parse filters extract data from fetched documents and can modify metadata and outlinks. Extend ParseFilter and implement the filter method.
import org.apache.stormcrawler.parse.ParseFilter;
import org.apache.stormcrawler.parse.ParseResult;
import com.fasterxml.jackson.databind.JsonNode;
import org.w3c.dom.DocumentFragment;
import java.util.Map;
public class MyParseFilter extends ParseFilter {
private String metadataKey;
@Override
public void configure(Map<String, Object> stormConf, JsonNode paramNode) {
metadataKey = paramNode.path("key").asText("custom-field");
}
@Override
public boolean needsDOM() {
return false; // set to true if you need the DOM tree
}
@Override
public void filter(String url, byte[] content, DocumentFragment doc,
ParseResult parse) {
// Extract data and store in metadata
parse.get(url).getMetadata().setValue(metadataKey, "extracted-value");
}
}Register it in parsefilters.json:
{
"org.apache.stormcrawler.parse.ParseFilters": [
{
"class": "com.example.MyParseFilter",
"name": "MyParseFilter",
"params": {
"key": "custom-field"
}
}
]
}If needsDOM() returns false for all configured parse filters, the parsing bolt skips DOM generation entirely, improving performance.
7.1.3. Custom Protocol
Protocol implementations define how content is fetched. Implement the Protocol interface:
import org.apache.stormcrawler.protocol.Protocol;
import org.apache.stormcrawler.protocol.ProtocolResponse;
import org.apache.stormcrawler.Metadata;
import crawlercommons.robots.BaseRobotRules;
import org.apache.storm.Config;
public class MyProtocol implements Protocol {
@Override
public void configure(Config conf) {
// Initialize from Storm configuration
}
@Override
public ProtocolResponse getProtocolOutput(String url, Metadata metadata)
throws Exception {
byte[] content = /* fetch content */;
int statusCode = 200;
Metadata responseMeta = new Metadata();
return new ProtocolResponse(content, statusCode, responseMeta);
}
@Override
public BaseRobotRules getRobotRules(String url) {
return RobotRulesParser.EMPTY_RULES;
}
@Override
public void cleanup() {}
}Register it in your configuration YAML:
http.protocol.implementation: "com.example.MyProtocol"
https.protocol.implementation: "com.example.MyProtocol"Use the DelegatorProtocol when you need to route URLs to different protocol implementations based on metadata or URL patterns.
7.1.4. Custom Page Action (Playwright)
The Playwright protocol exposes a PageAction extension point so you can plug site-specific post-navigate behaviour (tab/accordion expansion, cookie-banner dismissal, infinite-scroll, custom evaluate() calls, screenshotting, …) into the protocol without subclassing it. Actions are loaded as an ordered chain from a JSON file referenced by playwright.page.actions.config.file and follow the same Configurable lifecycle as URL/parse filters. The chain runs after page.navigate() succeeds and before page.content() is captured, so any DOM mutations land in the rendered content returned by the protocol.
A handful of built-in actions ship with the module — DismissOverlayAction, ExpandClickablesAction, ScrollToBottomAction, EvaluateAction, WaitForSelectorAction, ScreenshotAction. Reach for a custom action when none of those fit. Extend PageAction and implement apply:
import org.apache.stormcrawler.protocol.playwright.PageAction;
import org.apache.stormcrawler.Metadata;
import com.fasterxml.jackson.databind.JsonNode;
import com.microsoft.playwright.Page;
import java.util.Map;
public class MyPageAction extends PageAction {
private String selector;
@Override
public void configure(Map<String, Object> stormConf, JsonNode params) {
if (!params.has("selector")) {
throw new IllegalArgumentException("MyPageAction requires 'selector'");
}
this.selector = params.get("selector").asText();
}
@Override
public void apply(Page page, String url,
Metadata sourceMetadata, Metadata responseMetadata) {
page.locator(selector).click();
}
}Reference the action by its fully-qualified class name in the chain JSON:
{
"org.apache.stormcrawler.protocol.playwright.PageActions": [
{
"class": "com.example.MyPageAction",
"name": "my-action",
"params": { "selector": "#load-more" }
}
]
}Per-action failures in apply() are logged and swallowed by the chain wrapper so one bad action cannot abort the rest. If you need a hard failure on misconfiguration, throw from configure() — that propagates at topology start-up, before any URL is fetched.
7.1.5. Custom Bolt or Spout
For a bolt that emits on the status stream (like fetchers and parsers), extend StatusEmitterBolt:
import org.apache.stormcrawler.bolt.StatusEmitterBolt;
import org.apache.storm.tuple.Tuple;
public class MyBolt extends StatusEmitterBolt {
@Override
public void execute(Tuple tuple) {
String url = tuple.getStringByField("url");
byte[] content = tuple.getBinaryByField("content");
Metadata metadata = (Metadata) tuple.getValueByField("metadata");
// Process content...
collector.emit(tuple, new Values(url, content, metadata));
collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("url", "content", "metadata"));
declarer.declareStream(
org.apache.stormcrawler.Constants.StatusStreamName,
new Fields("url", "metadata", "status"));
}
}For a custom spout, extend BaseRichSpout and implement open(), nextTuple(), ack(), fail(), and declareOutputFields(). See FileSpout for a simple example. For spouts backed by a storage layer, extend AbstractQueryingSpout instead.
7.2. Politeness and Rate Limiting
StormCrawler enforces politeness at multiple levels to avoid overloading target servers.
7.2.1. Queue-Based Politeness
The FetcherBolt groups incoming URLs into queues based on the fetcher.queue.mode setting:
-
byHost(default) — one queue per hostname -
byDomain— one queue per registered domain (e.g.,sub.example.comandexample.comshare a queue) -
byIP— one queue per resolved IP address
Each queue enforces a minimum delay between consecutive requests. The delay is determined by:
-
The
Crawl-delaydirective in the site’srobots.txt(if present and within limits) -
The
fetcher.server.delaydefault (1 second) -
For multi-threaded queues,
fetcher.server.min.delayis used instead
7.2.2. Crawl-Delay Handling
When robots.txt specifies a Crawl-delay:
-
If the delay is smaller than
fetcher.server.delayandfetcher.server.delay.forceistrue, the larger default delay is used instead -
If the delay is larger than
fetcher.max.crawl.delay:-
fetcher.max.crawl.delay.force: false(default) — the queue is skipped and the URL gets an ERROR status -
fetcher.max.crawl.delay.force: true— the delay is capped atfetcher.max.crawl.delay
-
7.2.3. Robots.txt Compliance
StormCrawler fetches and caches robots.txt rules per host. The cache is configured via:
-
robots.cache.spec— Guava cache spec for valid rules (default: 6 hour expiry, 10000 entries) -
robots.error.cache.spec— cache spec for error responses (default: 1 hour expiry)
Individual aspects of robot compliance can be toggled:
-
http.robots.file.skip— ignorerobots.txtentirely -
http.robots.headers.skip— ignoreX-Robots-TagHTTP headers -
http.robots.meta.skip— ignore<meta name="robots">HTML tags -
robots.noFollow.strict— iftrue, remove all outlinks from pages marked asnoFollow
7.3. Error Handling and Retry Logic
StormCrawler uses a status-based system to handle errors and schedule retries.
7.3.1. Status Lifecycle
Each URL has a Status value that drives scheduling:
-
DISCOVERED — new URL, not yet fetched
-
FETCHED — successfully retrieved and processed
-
FETCH_ERROR — transient error (network timeout, HTTP 5xx). Will be retried.
-
ERROR — terminal error (too many retries, HTTP 4xx). Not retried by default.
-
REDIRECTION — HTTP 3xx redirect encountered
7.3.2. Retry Mechanism
When a URL receives FETCH_ERROR status, the AbstractStatusUpdaterBolt increments a fetch.error.count counter in the URL’s metadata. Once this counter reaches max.fetch.errors (default: 3), the status is escalated to ERROR.
The DefaultScheduler computes the next fetch date based on status:
-
FETCHED —
fetchInterval.default(default: 1440 minutes = 1 day) -
FETCH_ERROR —
fetchInterval.fetch.error(default: 120 minutes = 2 hours) -
ERROR —
fetchInterval.error(default: -1 = never refetch)
On a successful fetch, the error counter and error metadata (error.cause, error.message, error.source) are cleared automatically.
7.3.3. Custom Fetch Intervals
You can set fetch intervals based on metadata key-value pairs:
# All feeds refetch every 10 minutes
fetchInterval.isFeed=true: 10
# Feeds with fetch errors retry after 60 minutes
fetchInterval.FETCH_ERROR.isFeed=true: 607.4. Monitoring and Metrics
StormCrawler exposes metrics through Apache Storm’s built-in metrics system. Bolts register counters, gauges, and averages which are reported at configurable intervals.
7.4.1. Key Fetcher Metrics
The FetcherBolt tracks:
-
fetcher_counter— event counts (fetched, error, redirection, robots_rules_fetches) -
fetcher_average— averaged values (download_time, queue_wait_time) -
fetcher_average_persec— throughput rates (fetched_per_sec, error_per_sec) -
activethreads— number of currently active fetching threads
The reporting interval is controlled by fetcher.metrics.time.bucket.secs (default: 10 seconds).
7.4.2. Metrics Consumers
To persist metrics, register a MetricsConsumer in your topology configuration:
topology.metrics.consumer.register:
- class: "org.apache.stormcrawler.opensearch.metrics.MetricsConsumer"
parallelism.hint: 1StormCrawler provides MetricsConsumer implementations for OpenSearch, Solr, and SQL.
The Storm UI (default port 8080) provides real-time visibility into topology health, including execute/process latency, emit counts, and error rates per bolt and spout.
7.5. Scaling and Tuning
7.5.1. Thread and Parallelism Tuning
-
fetcher.threads.number— total fetching threads across all queues (default: 10). Increase for broader crawls. -
fetcher.threads.per.queue— threads per host/domain/IP queue (default: 1). Increase only for sites that allow aggressive crawling. -
fetcher.maxThreads.host/domain/ip— override threads for a specific queue. -
protocol.instances.num— number of protocol instances (default: 1). Increase for OkHttp connection pool efficiency.
In Flux or topology code, set parallelism for each bolt to control Storm executor allocation. Increase spout parallelism when the frontier is the bottleneck.
7.5.2. Queue and Buffer Tuning
-
fetcher.max.urls.in.queues— caps total queued URLs to prevent memory exhaustion. -1 for unlimited. -
fetcher.max.queue.size— caps individual queue length. -
urlbuffer.class— URL buffer implementation used by spouts. The defaultSimpleURLBufferis suitable for most use cases.
7.5.3. Memory and Connection Pooling (OkHttp)
For crawls with many concurrent hosts, tune OkHttp’s connection pool:
okhttp.protocol.connection.pool:
max.idle.connections: 5
connection.keep.alive: 300Keep the pool size (idle + active) under 1000. For large crawls, increase protocol.instances.num to distribute connections across multiple pools.
7.6. Security Considerations
7.6.1. SSL/TLS
By default, StormCrawler’s OkHttp protocol trusts all certificates (http.trust.everything: true). For production crawls over untrusted networks, consider setting this to false and configuring a proper trust store.
7.6.2. Authentication
Basic Authentication is supported via:
http.basicauth.user: "username"
http.basicauth.password: "password"These credentials are sent as an Authorization header with every request. For per-site authentication, use metadata-driven headers instead (see [Metadata-dependent Behavior For HTTP Protocols] in the Internals section).
7.6.3. Proxy Authentication
Proxy credentials can be configured via:
http.proxy.host: "proxy.example.com"
http.proxy.port: 8080
http.proxy.user: "proxyuser"
http.proxy.pass: "proxypass"For rotating proxies, use the MultiProxyManager with a proxy list file. See the Proxy configuration section for details.
8. Debugging a StormCrawler Topology
Assuming you have a StormCrawler setup all ready to use (e.g., generated from the archetype), you can debug it by either:
-
Running the Java topology from your IDE in debug mode.
-
Using the following command to enable remote debugging:
export STORM_JAR_JVM_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=localhost:8000"Then run the topology in the usual way with storm jar ... and remote debug from your IDE.
In both cases, the topology will need to run in local mode, i.e., not deployed to a Storm cluster.
9. Companies & Projects Using StormCrawler
Apache StormCrawler has been adopted by a wide variety of organizations across industries, from startups to large enterprises and research institutions. The following is a non-exhaustive list of companies, projects, and institutions that have used Apache StormCrawler in production or research. If your organization is also making use of Apache StormCrawler, we’d love to hear from you!
Drop us a line at dev@stormcrawler.apache.org if you want to be added to this page.
10. Talks, tutorials, articles and interviews
-
OWler: preliminary results for building a collaborative open web crawler, Dinzinger and al., OSSYM 2023 https://ca-roll.github.io/downloads/owler.pdf
-
Presentation: StormCrawler and OpenSearch (Feb 2023) https://www.youtube.com/watch?v=azHYI9pnjos
-
Crawling the German Health Web: Exploratory Study and Graph Analysis, Zowalla R, Wetter T, Pfeifer D. J Med Internet Res 2020;22(7):e17853 https://www.jmir.org/2020/7/e17853
-
Tutorial: StormCrawler 1.16 + Elasticsearch 7.5.0 https://youtu.be/8kpJLPdhvLw
-
StormCrawler open source web crawler strengthened by Elasticsearch, Kibana https://www.elastic.co/blog/stormcrawler-open-source-web-crawler-strengthened-by-elasticsearch-kibana
-
Harvesting Online Health Information, Richard Zowalla slides
-
Tutorial: StormCrawler 1.10 + Apache SOLR 4.7.0 https://youtu.be/F8nvGj03XLo
-
Patent-Crawler: A Web Crawler to Gather Virtual Patent Marking Information, Etienne Orliac, l’Université de Lausanne/École Polytechnique Fédérale de Lausanne (UNIL/EPFL) slides - video
-
DigitalPebble’s Blog: Crawl dynamic content with Selenium and StormCrawler https://digitalpebble.blogspot.co.uk/2017/04/crawl-dynamic-content-with-selenium-and.html
-
The Battle of the Crawlers: Apache Nutch vs. StormCrawler https://dzone.com/articles/the-battle-of-the-crawlers-apache-nutch-vs-stormcr
-
Tutorial: StormCrawler + Elasticsearch + Kibana https://digitalpebble.blogspot.co.uk/2017/04/video-tutorial-stormcrawler.html
-
Q&A with InfoQ https://www.infoq.com/news/2016/12/nioche-stormcrawler-web-crawler
-
DigitalPebble’s Blog: Index the web with StormCrawler (revisited) https://digitalpebble.blogspot.co.uk/2016/09/index-web-with-stormcrawler-revisited.html
-
DigitalPebble’s Blog: Index the web with AWS CloudSearch https://digitalpebble.blogspot.co.uk/2015/09/index-web-with-aws-cloudsearch.html
-
Low latency scalable web crawling on Apache Storm slides - video, by Julien Nioche. BerlinBuzzwords 2015
-
Storm Crawler: A real-time distributed web crawling and monitoring framework slides, by Jake Dodd - Ontopic, ApacheCon North America 2015
-
A quick introduction to Storm Crawler slides, by Julien Nioche. ApacheCon Europe, Budapest, Nov 2014
-
StormCrawler in the wild slides, by Jake Dodd - Ontopic, ApacheCon Europe, Budapest, Nov 2014
Drop us a line at dev@stormcrawler.apache.org if you want to be added to this page.